
Los algoritmos están presentes en nuestra vida cotidiana de muchas maneras, pero ¿sabemos realmente qué son, cómo funcionan y para qué sirven?
Los algoritmos están presentes en nuestra vida cotidiana de muchas maneras, pero ¿sabemos realmente qué son, cómo funcionan y para qué sirven?

Muchas veces escuchamos nombrar los algoritmos, sabemos que nos recomiendan servicios y productos en las plataformas: desde ropa, películas y comidas, pasando por la ruta que nos conviene tomar, hasta contratar a alguien o no contratarlo para un puesto de trabajo, detectar enfermedades, elegir una posible pareja o comprender un poco más sobre los procesos de aprendizaje. Pero la influencia de los algoritmos no se agota en estos ejemplos. Gran parte del funcionamiento de la economía, la política, la sociedad, la cultura y los vínculos está mediada por algoritmos, de ahí la gran importancia de entender cómo se generan y, sobre todo, de qué modos nos afectan.
¿Qué son los algoritmos?
Los algoritmos son creaciones humanas, no tienen nada de mágico o misterioso; tampoco hace falta saber sobre súper computadoras, ciencia de datos o altísimas potencias de cálculo y predicciones —aunque también tienen mucho que ver con todo esto- para comprenderlos un poco más.
La manera más simple de definir a los algoritmos, es decir, que son recetas o una lista de pasos a seguir para desarrollar una tarea o una serie de instrucciones para hallar la solución de un problema o un programa para lograr un objetivo. Ese objetivo puede ser muy elemental o extremadamente complejo.
El algoritmo para preparar gelatina de agua, por ejemplo, es muy simple y fácil. Lo tenemos tan incorporado y naturalizado, que cuando hacemos gelatina ni siquiera pensamos en los diferentes pasos que hay que seguir, sino que actuamos automáticamente.
Este es el algoritmo que incluye la lista de instrucciones para preparar una gelatina:
- Iniciar la preparación.
- Alistar los ingredientes y utensilios necesarios.
- Verter un litro de agua en una olla.
- Poner la olla en la hornalla o estufa y esperar a que hierva.
- Cuando hierva, apagar la hornalla o estufa, agregar el contenido del sobre de gelatina al agua hervida y esperar 5 minutos, sin dejar de revolver — hasta que se haya disuelto por completo la gelatina.
- Una vez disuelta la gelatina, dejarla reposar hasta que alcance temperatura ambiente.
- Pasar la gelatina a un recipiente y dejarla en la heladera un par horas hasta que cuaje.
- Servir la gelatina.
- Fin de la preparación.
Los algoritmos que intervienen, por ejemplo, en la guía, navegación y control de satélites que orbitan en el espacio son complejos. Sin embargo, hacer una gelatina y poner en órbita un satélite requieren básicamente lo mismo: una serie de instrucciones, ya sea una receta o un programa.
La cultura digital de nuestro presente, se construyó en torno a enormes cantidades de datos y grandes volúmenes de información que fluyen a velocidades exponenciales en un planeta hiperconectado por redes.
Podríamos escribir cientos de algoritmos relacionados con nuestras acciones cotidianas: lavarnos los dientes, tomar el colectivo, sacar dinero del cajero automático, hacer un recorrido en bicicleta, realizar una rutina de elongación muscular, hacer las compras del supermercado, preparar una clase, tocar la guitarra, ordenar un ropero, enviar un correo electrónico, etc. Recomendamos hacer el ejercicio de escribir los algoritmos de todo lo que nos pasa inadvertido.

Algoritmos y big data
Los seres humanos tenemos una habilidad muy especial, que es la de manipular símbolos. A lo largo de nuestra historia, cada avance en esta capacidad produjo transformaciones muy significativas a nivel económico, social, político, científico y educativo. Estos cambios, que trazaron una evolución cultural, van desde las pinturas rupestres, los rituales y narrativas primigenios, la invención de la escritura, la creación de alfabetos y sistemas numéricos, pasando por la fabricación de un artefacto como la imprenta, hasta arribar al desarrollo de sistemas simbólicos innovadores que procesan la información a través de algoritmos.
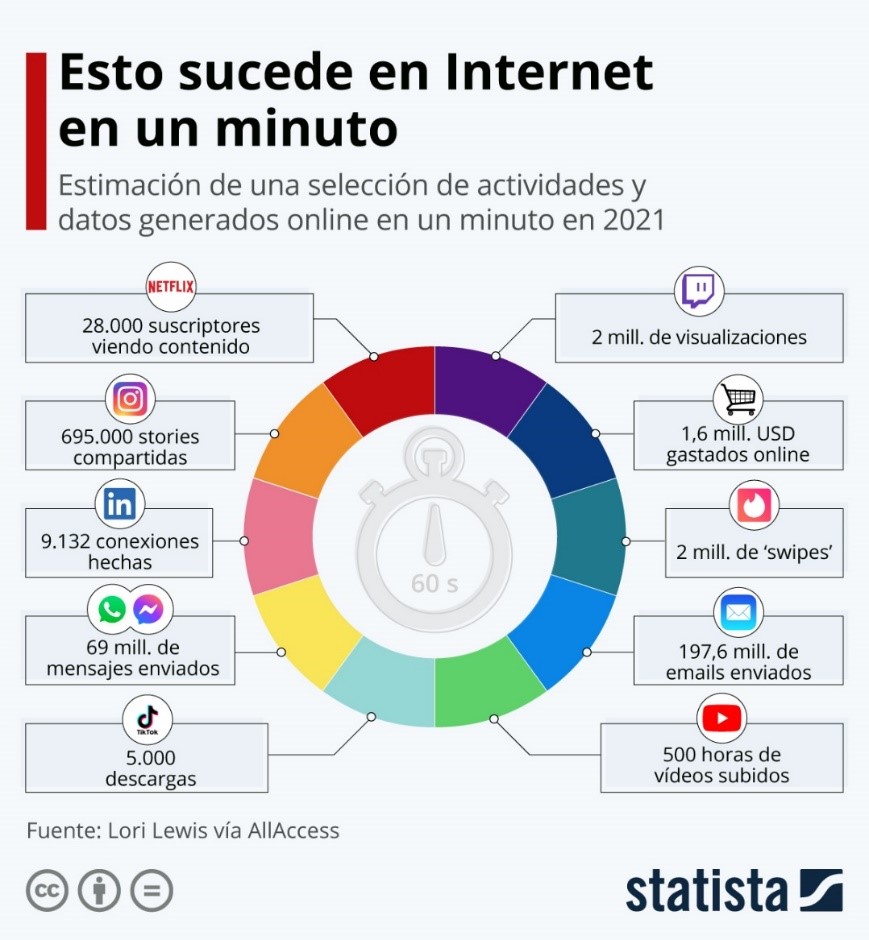
La cultura digital de nuestro presente se construyó, principalmente, en torno a enormes cantidades de datos y grandes volúmenes de información que fluyen a velocidades exponenciales en un planeta hiperconectado por redes. Repasar algunos números y cifras exorbitantes, nos ayudará a comprender que solo los algoritmos son capaces de localizar, recolectar, analizar, organizar e interpretar cantidades masivas de datos, conocidas como big data o macrodatos.
En este momento hay, aproximadamente, 5231 millones de usuarios de Internet en el mundo, solamente en el día de hoy se realizaron aproximadamente 5600 millones de búsquedas en Google y se enviaron 180 mil millones de correos electrónicos y 549 millones de tweets. En cuanto a la información, los bytes son las unidades de información y, ahora mismo, en el mundo se están manejando enormes cantidades de información en zettabytes (ZB). 1 zettabyte = 1.000 exabytes = 1 millón de petabytes = 1000 millones de terabytes.
Para tratar de comprender las dimensiones de estas cantidades y sus flujos, pensemos en que el peso aproximado de toda Internet en el año 2015 fue de 8 zettabytes, en el año 2018 superó fácilmente los 10 zettabytes y, en 2020, esta cantidad pudo haberse duplicado. En cuanto al volumen total de datos que se produjeron en el mundo: en 2015 hubo 15.5 ZB, en 2020 se estimaron 50,5 ZB y para finales de 2025, se calcula que habrá una producción de 175 ZB de datos.
De la inteligencia colectiva a la inteligencia algorítmica
Antes de avanzar un poco más con los algoritmos, nos detendremos un instante a repasar el concepto de inteligencia colectiva, estudiado por Pierre Lévy. Hace casi 30 años, este filósofo e investigador tunecino-francés, anticipó que Internet estaba llamada a convertirse en la plataforma contemporánea de la inteligencia colectiva humana por su posibilidad de mejorar sustancialmente la gestión del conocimiento y hacerlo en tiempo real.
La anticipación de Lévy se cumplió: Internet no es un medio más, sino un metamedio, un medio de medios donde la información fluye de modo ultra veloz y donde la interactividad e intercambio ocurren —gran parte— en los espacios virtuales de las redes y plataformas digitales.
La inteligencia colectiva no es algo que se crea desde cero, sino que ya existe. De hecho, su existencia puede constatarse de un modo muy gráfico en el mundo animal: el comportamiento de los insectos sociales, por ejemplo, permite comprenderla de una manera simple.
Pensemos en una hormiga que va caminando y encuentra unas pequeñas migajas de pan. La hormiga toma un trocito y lo lleva hacia el hormiguero. De regreso al hormiguero, ella deja una huella química, esa huella son trazas de feromonas. Y deja esas trazas cada vez que va y viene. Lo que hace la hormiga es modificar el ambiente. Al liberar sus feromonas en el entorno genera un «mensaje», es decir, produce información que será tomada e interpretada por otras hormigas que irán a buscar más alimento.
La hormiga del ejemplo modificó el ambiente que comparte con otras hormigas, lo hizo alterando el espacio común a todas, produciendo un hecho de comunicación y esta transformación propició que emergiera una memoria. Ahora las otras hormigas conocen el camino hacia las migajas de pan. Esto es inteligencia colectiva.

Los seres humanos también tenemos, como las hormigas y los delfines, inteligencia colectiva. Pero, a diferencia del resto de los animales, los humanos desarrollamos un lenguaje complejo, generamos tecnología cada vez más avanzada, organizamos instituciones y llevamos a cabo interacciones sociales, culturales y económicas muy sofisticadas.
En otras palabras, las personas dejamos enormes cantidades de migajas de pan en todas las redes y plataformas, generamos hechos de comunicación por millones y millones y millones, de manera cada vez más compulsiva y confiamos demasiado en la eficiencia de los algoritmos para gestionar esa masa de datos e información de crecimiento imparable. Según Levy, estaríamos pasando de una inteligencia colectiva a una inteligencia algorítmica.
Confiamos demasiado en la eficiencia de los algoritmos para gestionar esa masa de datos e información de crecimiento imparable.
¿Cómo funcionan los algoritmos?
El aprendizaje de los algoritmos se incrementa día a día y depende de cómo los programamos. Pero ¿qué hace un algoritmo?
En función de la masa de datos que analiza:
- realiza un diagnóstico.
- formula una hipótesis.
- Interpreta.
Lo importante de esto es que, frente a los big data, frente a los millones, billones, trillones y cantidades de datos incalculables para la capacidad humana, un algoritmo baraja cientos de miles de hipótesis e interpreta información a velocidades inimaginables.
Es muy importante no perder de vista que somos los seres humanos los que creamos y “alimentamos” los algoritmos con todos los datos que generamos. Los algoritmos no aparecen de la nada con entidad propia y deciden lo que se les ocurre; son programas diseñados por personas con objetivos específicos.
Una de las grandes preocupaciones de nuestro presente es la cuestión ética detrás del funcionamiento de las gigantescas estructuras algorítmicas. La “mirada algorítmica” no es sensible, se construye con instrucciones para un programa con determinado objetivo. Sensibles, sesgadas y/o prejuiciosas: son las acciones de las personas, las compañías, las empresas y los Estados que “entrenan” los algoritmos. Por lo tanto, las interpretaciones de los datos que hacen algunos algoritmos pueden resultar discriminatorias. Muchas personas y organizaciones están preocupadas por estos prejuicios y hablan de injusticia algorítmica.
La Liga de la Justicia Algorítmica
Joy Buolamwini, científica informática en el Media Lab del Instituto tecnológico de Massachusetts, comenzó a investigar las disparidades raciales, de tipo de piel y de género que arrojaban los algoritmos de las tecnologías de reconocimiento facial disponibles comercialmente. Su investigación culminó en dos estudios innovadores revisados por pares, publicados en 2018 y 2019, que revelaron cómo los algoritmos de Amazon, IBM y Microsoft, entre muchos otros, no pudieron clasificar los rostros femeninos más oscuros con tanta precisión como los de los hombres blancos, lo que hizo añicos el mito de la “neutralidad” de los algoritmos.
Hoy, Buolamwini está impulsando un movimiento creciente para exponer las consecuencias sociales de los sesgos algorítmicos y trabajar para “educar a los algoritmos”. A través de su organización sin fines de lucro conocida como La Liga de la Justicia Algorítmica, ha testificado ante legisladores a nivel federal, estatal y local sobre los peligros de usar tecnologías de reconocimiento facial sin supervisión de cómo se crean o implementan. Desde la muerte de George Floyd, asfixiado por un policía en Estados Unidos, ha pedido que se detenga por completo el uso policial de la vigilancia de reconocimiento facial y está proporcionando a los activistas recursos y herramientas para exigir la regulación. Muchas empresas, siguen vendiendo esta tecnología a la policía y agencias gubernamentales. Y muchos departamentos de policía están utilizando tecnologías de reconocimiento facial para identificar individuos que han cometido, están cometiendo o están a punto de cometer delitos. Fuente Fast Company
Sugerimos activar los subtítulos en español.
Por ejemplo, en Argentina, el gobierno de la ciudad de Buenos Aires, desde el jueves 25 de abril de 2019, sumó un nuevo sistema de Reconocimiento Facial, cuyos datos, le permiten a la Policía de la Ciudad localizar y detener a personas prófugas mediante la detección de rostros a través de las 300 cámaras de video-vigilancia que están instaladas en diferentes calles y estaciones de la red de subte El reconocimiento de rostros se realiza desde diversos ángulos y condiciones de iluminación, aún ante cambios de apariencia como anteojos, barba, bigote, gorro, sombrero o cambio de peinado. Si bien los defensores del uso del reconocimiento facial aseguran que el género de la persona se puede detectar en una fotografía con una precisión del 99% y su edad con una precisión del 95% dentro un umbral de tres años, el problema de los sesgos y errores, descrito por Joy Buolamwini, indica que esta tecnología vulnera la privacidad y la seguridad de las personas y su eficacia no está comprobada.

No se debe tener confianza ciega en el Big Data porque los algoritmos pueden ser “opiniones” que se embeben en códigos de programación.
En la misma línea de preocupación por los sesgos algorítmicos, Catherine Helen O’Neil, doctora en matemáticas por la Universidad de Harvard, experta en procesamiento de datos y algoritmos, autora de varios libros sobre ciencia de datos, señala que no se debe tener confianza ciega en los big data porque los algoritmos pueden ser “opiniones” que se embeben en códigos de programación. Hay que “educar” a los algoritmos creando códigos más inclusivos. RM
Sugerimos activar los subtítulos en español.
La nota “Los algoritmos de cada día” fue publicada originalmente en el portal Educ.ar https://www.educ.ar/recursos/155990/los-algoritmos-de-cada-dia-parte-1




